Table Of Content
The effect of these changes in colors is to show the twist in the plane. In the middle - the points in black, they are pretty much in a straight line - they are following a normal distribution. In other words, their expectation or percentile is proportionate to the size of the effect. The ones in red are like outliers and stand away from the ones in the middle and indicate that they are not just random noise but there must be an actual affect. Without making any assumptions about any of these terms this plot is an overall test of the hypothesis based on simply assuming all of the effects are normal.
Extension to a 3 Factor Model
As we will see, interactions are often among the most interesting results in empirical research. A 2×2 factorial design is a type of experimental design that allows researchers to understand the effects of two independent variables (each with two levels) on a single dependent variable. Figure 5.3 shows results for two hypothetical factorial experiments. Time of day (day vs. night) is represented by different locations on the x-axis, and cell phone use (no vs. yes) is represented by different-colored bars. It would also be possible to represent cell phone use on the x-axis and time of day as different-colored bars. The choice comes down to which way seems to communicate the results most clearly.
Factorial Designs with 2 Treatment Factors, cont'd
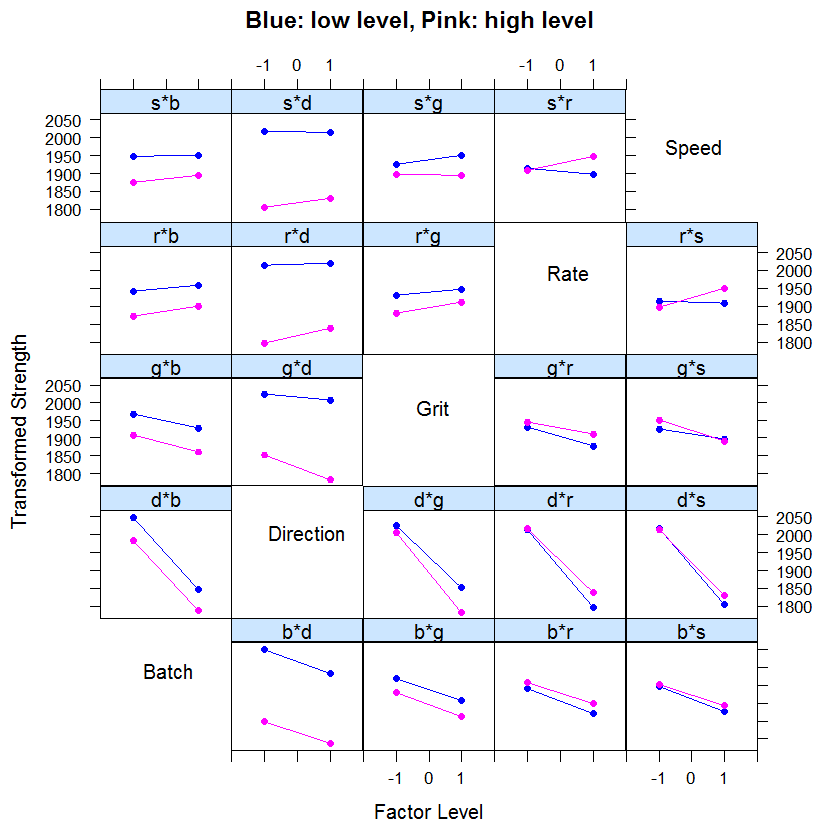
Factorial experiments allow subtle manipulations of a larger number of interdependent variables. Whilst the method has limitations, it is a useful method for streamlining research and letting powerful statistical methods highlight any correlations. Before we get to the analysis, however, we want to introduce another definition of effects - rather than defining the \(\alpha_i\) effects as deviation from the mean, we can look at the difference between the high and the low levels of factor A. These are two different definitions of effects that will be introduced and discussed in this chapter and the next, the \(\alpha_i\) effects and the difference between the high and low levels, which we will generally denote as the A effect. Like Pareto plots, Half Normal plots show which factors have significant effects on the responses.
Implementing Clinical Research Using Factorial Designs: A Primer
A 2 means that the independent variable has two levels, a 3 means that the independent variable has three levels, a 4 means it has four levels, etc. To illustrate, a 3 x 3 design has two independent variables, each with three levels, while a 2 x 2 x 2 design has three independent variables, each with two levels. Just as including multiple dependent variables in the same experiment allows one to answer more research questions, so too does including multiple independent variables in the same experiment. For example, instead of conducting one study on the effect of disgust on moral judgment and another on the effect of private body consciousness on moral judgment, Schnall and colleagues were able to conduct one study that addressed both variables.
The lesson here, therefore, is to spend more time sleeping and studying, and less time with your boyfriend or girlfriend. As seen above, RPM is shown with a positive effect for number of theoretical stages, but a negative effect for wt% methanol in biodiesel. A positive effect means that as RPM increases, the number of theoretical stages increases. Whereas a negative effect indicates that as RPM increases, the wt% methanol in biodiesel decreases.
Effects and Interaction Plots
However, there are risks…if there is only one observation at each corner, there is a high chance of an unusual response observation spoiling the results. There would be no way to check if this was the case and thus it could distort the results fairly significantly. You have to remind yourself that these are not the definitive experiments but simply just screening experiments to determine which factors are important. This is important because, as always, one must be cautious about inferring causality from correlational studies because of the directionality and third-variable problems.

The Main Total Effect can be related to input variables by moving along the row and looking at the first column. If the row in the first column is a2b1c1 then the main total effect is A. To get a mean factorial effect, the totals needs to be divided by 2 times the number of replicates, where a replicate is a repeated experiment. Regardless of whether the design is between subjects, within subjects, or mixed, the actual assignment of participants to conditions or orders of conditions is typically done randomly. We will set this up the same way in Minitab and this time Minitab will show the plot in three dimensions, two variables at a time. In these experiments one really cannot model the "noise" or variability very well.
The Impact and Implications of the COVID-19 Pandemic on the Design of a Laboratory-Based Coaching Science ... - United States Sports Academy Sports Journal
The Impact and Implications of the COVID-19 Pandemic on the Design of a Laboratory-Based Coaching Science ....
Posted: Fri, 01 Oct 2021 07:00:00 GMT [source]
Lesson 5: Introduction to Factorial Designs
This is less clear because the effect is smaller so it is harder to see. You can look at the red bars first and see that the red bar for no-shoes is slightly smaller than the red bar for shoes. The green bar for no-shoes is slightly smaller than the green bar for shoes. Imagine an aquaculture research group attempting to test the effects of food additives upon the growth rate of trout. Next, using Operator as a block we will now use Minitab v19 to treat the quantitative factors as qualitative factors and apply these in a regression analysis.
3 - Unreplicated \(2^k\) Factorial Designs
In addition, the use of a large number of factors allows for built-in evaluations of the robustness of the main effects of the ICs. This is because, as noted earlier, such effects are determined by averaging over the other component effects (with effect coding). In sum, in a factorial experiment, the effects, relative effects, and statistical significance of ICs will likely change depending upon the number and types of components that co-occur in the experimental design.
This is a very helpful - a good quick and dirty first screen - or assessment of what is going on in the data, and this corresponds exactly with what we found in our earlier screening procedures. Even with just one observation per cell, by carefully looking at the results we can come to some understanding as to which factors are important. We do have to take into account that these actual p-values are not something that you would consider very reliable because you are fitting this sequence of models, i.e., fishing for the best model. We have optimized with several decisions that invalidates the actual p-value of the true probability that this could have occurred by chance. Notice also the use of the Yates notation here that labels the treatment combinations where the high level for each factor is involved. If only A is high then that combination is labeled with the small letter a.
Actually, at the beginning of our design process, we should decide how many observations we should take, if we want to find a difference of D, between the maximum and the minimum of the true means for the factor A. Note that both a and b are 2, thus our marginal row means are 8 and 12, and our marginal column means are 7 and 13. Next, let's calculate the \(\alpha\) and the \(\beta\) effects; since the overall mean is 10, our \(\alpha\) effects are -2 and 2 (which sum to 0), and our \(\beta\) effects are -3 and 3 (which also sum to 0). If our distraction manipulation is super-distracting, then what should we expect to find when we compare spot-the-difference performance between the no-distraction and distraction conditions? If our manipulation works, then we should find that people find more differences when they are not distracted, and less differences when they are distracted.
Since the main total factorial effect for AB is non-zero, there are interaction effects. This means that it is impossible to correlate the results with either one factor or another; both factors must be taken into account. The following Yates algorithm table using the data from the first two graphs of the main effects section was constructed. Besides the first row in the table, the row with the largest main total factorial effect is the B row, while the main total effect for A is 0.
However, the Normal Plot displays whether the effect of the factor is positive or negative on the response. Once the terms have been chosen, the next step is determining which graphs should be created. The types of graphs can be selected by clicking on "Graphs..." in the main "Analyze Factorial Design" menu.
When we introduced this topic we wouldn't have dreamed of running an experiment with only one observation. As a matter of fact, the general rule of thumb is that you would have at least two replicates. This would be a minimum in order to get an estimate of variation - but when we are in a tight situation, we might not be able to afford this due to time or expense. We will look at an example with one observation per cell, no replications, and what we can do in this case.








No comments:
Post a Comment